性能分析方法论及策略——传统方法与 BPF 方法
性能,性能,还是不得不谈的性能!无论是 PC、智能手机、云计算服务器,还是嵌入式系统,性能都扮演着至关重要的角色,是用户体验的关键,是决定业务成功与否的重要因素。
然而,要实现卓越的性能并不是一项轻而易举的任务。性能优化需要广泛的知识和技能,涵盖软件、硬件和许多其他领域。这是一场无休止的挑战,但也是一个充满激情的技术战场。
本文将从系统维护者的角度对性能优化相关的方法论进行梳理,并特别阐述新生的 eBPF 给性能分析领域带来的影响。由于不同读者的知识领域并不完全相同,所以本文将不会涉及到具体实现,但只要读者有性能优化的需求,那么本文可能就会有所裨益。
性能分析方向
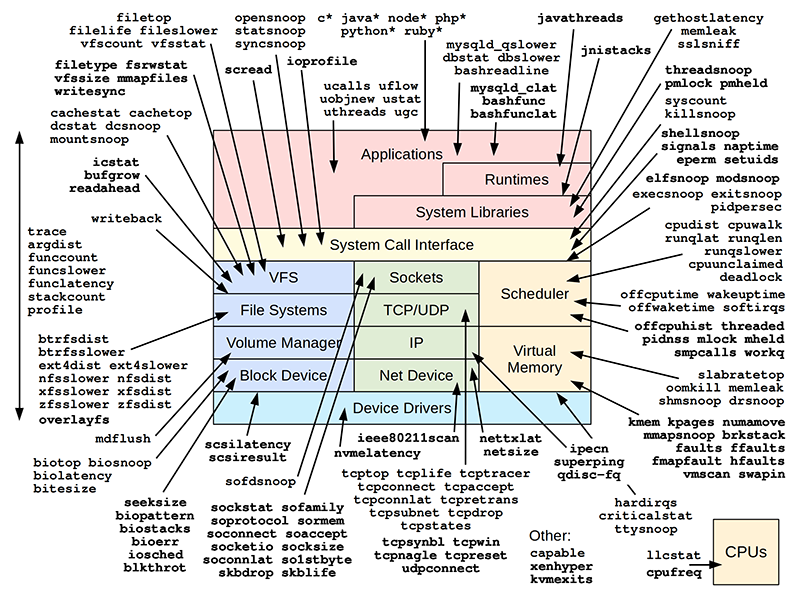
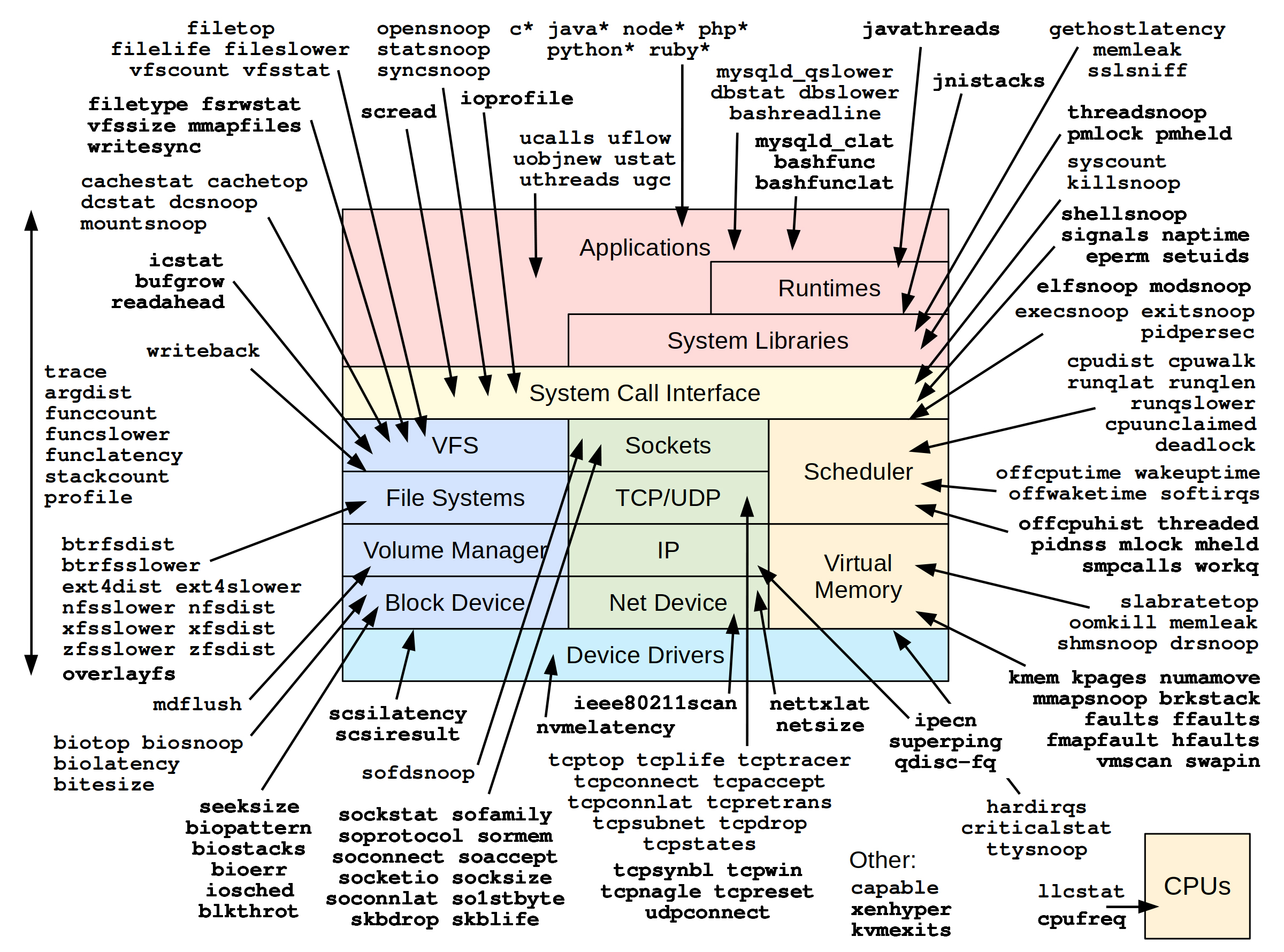
下图是从用户态(🟥)和系统调用(🟨)到内核态(文件系统 I/O:🟦、网络:🟩、调度和内存:🟧)和设备驱动(浅蓝)的全景图,其中每个色块代表的组成部分又分为若干个子系统,旁边的箭头指的是对应子系统有哪些可以用来执行分析的 BPF 工具。在如此众多的分析方向进行性能分析,如果没有方法论的指导,将必然会陷入迷茫。因此下文将细化到性能分析全景图的每个部分,阐述性能分析方法论及其策略。
性能分析方法论
优化目标
性能分析的最终目标就是优化用户体验、降低系统运行成本。这就需要观测软件和硬件资源是如何被使用的,以及从中定位可优化的部分。为了知道系统当前的工作状态,并确定优化措施是否生效,我们首先需要定义一些指标进行衡量。最常用的指标包括如下几项:
- 延迟:多久可以完成一次请求或操作,通常以毫秒为单位。
- 速率:每秒操作或请求的速率。
- 吞吐量:通常指每秒传输的数据量,以比特(bit)或者字节(byte)为单位。
- 利用率:以百分比形式表示的某资源在一段时间内的繁忙程度。
- 成本:开销与性能的比值。
业务负载画像
业务负载画像的目的是理解实际运行的业务负载,而并不需要对最终的性能结果进行分析,比如系统的延迟到底受到多少影响。
开展业务负载画像的常用步骤如下:
- 负载是谁产生的(进程 ID、用户 ID、进程名、IP 地址)
- 负载为什么会产生(代码路径、调用栈、火焰图)
- 负载的组成是什么(IOPS、吞吐量、负载类型)
- 负载怎样随着时间发生变化(比较每个周期的摘要信息)
下钻分析
下钻分析的工作过程是从一个指标开始,然后将这个指标拆分成多个组成部分,再将最大的组份进一步拆分为更小的组份,不断重复这个过程直到定位出一个或多个根因。
下钻分析的常用步骤如下:
- 从业务最高层级开始分析。
- 检查下一个层级的细节。
- 挑选出最感兴趣的部分或者线索。
- 如果问题还没有解决,跳转至第 2 步继续递归执行。
下面举一个例子来讲解下钻分析如何将延迟分解为各个部分:
- 一个请求的延迟是 100ms。
- 其中有 10ms 在 CPU 上运行(on CPU),90ms 消耗在脱离 CPU 的等待过程(off CPU)。
- 在脱离 CPU 等待的部分中,有 89ms 阻塞于文件系统上。
- 在文件系统的处理过程中,有 3ms 阻塞于锁上,而 86ms 阻塞于存储设备上。
考虑一个类似的场景,但是问题的根本原因可能并不相同:
- 一个应用花费了 89ms 阻塞在文件系统上。
- 文件系统花费了 78ms 阻塞在写操作上,11ms 阻塞在读操作上。
- 在文件系统写操作中,耗费了 77ms 阻塞在时间戳的更新上。
此时,可以得出的结论是:更新时间戳是延迟的根源,而这是可以通过改变一个挂载选项禁掉的。这个分析结果说明的原因(系统配置问题)就和上一个场景(磁盘性能问题)完全不同。
USE 方法论
USE 方法论也可以用来进行资源分析。主要做法就是检查所有资源的使用率(Utilization)、饱和度(Saturation)、错误(Errors)。以重要的问题作为开始,反过来再去找出为什么它重要。
检查清单法
在系统出现性能问题时,一个茫然无措的管理员可以通过一系列成规范的命令快速检测系统工作状态(开始检测的 60 秒内)。下面就是这些命令及其含义。
| 命令 | 含义 | |
|---|---|---|
| 1 | uptime |
1 分钟、5 分钟、15 分钟内的平均负载 |
| 2 | dmesg | tail |
过去 10 条操作系统日志 |
| 3 | vmstat 1 |
虚拟内存相关:等待执行的进程数、空闲内存、交换内存、各种状态的 CPU 运行时间(user time、system time、idle、wait I/O 和 stolen time) |
| 4 | mpstat -P ALL 1 |
每个 CPU 分解到各个 CPU 状态下的时间 |
| 5 | pidstat 1 |
按进程逐秒展示 CPU 的使用情况 |
| 6 | iostat -xz 1 |
存储设备 I/O 相关:每秒向设备发送的读/写次数和字节数、I/O 的平均响应时间、设备请求队列的平均长度、设备使用率 |
| 7 | free -m |
可用内存 |
| 8 | sar -n DEV 1 |
各网络设备吞吐量 |
| 9 | sar -n TCP,ETCP 1 |
接受连接速率、创建连接速率、每秒 TCP 重传量 |
| 10 | top |
综合上述工具的检测手段,用于二次确认 |
特别地,BPF 工具也能用于性能分析和检查,并会有不一样的视角和效果。BCC 是基于 BPF 实现的 Linux 内核技术,可以广泛用于 I/O 分析、网络操作和系统监控。当前 BCC 中已经有很多支持即插即用的工具,能够在多个方面实现系统监控,所以这里也有一组由 BCC 工具组成的检查清单。
| BCC 工具 | 监测维度 | |
|---|---|---|
| 1 | execsnoop |
创建新进程 |
| 2 | opensnoop |
打开文件 |
| 3 | ext4slower(或 btrfs*、xfs*、zfs*) |
文件系统延迟 |
| 4 | biolatency |
磁盘 I/O 延迟分布 |
| 5 | biosnoop |
磁盘 I/O 延迟详细信息 |
| 6 | cachestat |
文件系统缓存性能 |
| 7 | tcpconnect |
TCP 发起连接 |
| 8 | tcpaccept |
TCP 接受连接 |
| 9 | tcpretrans |
TCP 重传 |
| 10 | runqlat |
调度延迟 |
| 11 | profile |
CPU 使用情况 |
性能分析策略
一般情况下,在出现性能问题时,管理员可以通过上述某些检查清单初步定位系统问题。但是,定位到问题所在的位置之后呢?我们应该如何继续“下钻”下去?这个时候就需要针对不同的子系统采取不同的分析策略。
CPU
CPU 分析策略
- 先保证待分析的对象处于 CPU 运行状态。检查系统的整体 CPU 利用率(使用
mpstat(1)),并且保证每个 CPU 都处于在线状态(检查是否有些 CPU 由于某些原因处于下线状态)。 - 确认系统负载确实受限于 CPU。
- 确认系统中所有 CPU 的使用率是否都很高,还是仅某个 CPU 使用率高(
mpstat(1))。 - 检查系统中运行队列的延迟(使用 BCC 工具
mnqlat(1))。系统中的一些软件限制(比如容器的设置)可以限制进程所能使用的 CPU 资源,进而导致某些程序在空闲系统上仍然受限于 CPU。通过分析运行队列延迟可以识别这种类型的反常情景。
- 确认系统中所有 CPU 的使用率是否都很高,还是仅某个 CPU 使用率高(
- 先量化整个系统中的 CPU 使用量的百分比,然后再按进程、CPU 模式、CPU ID 来分解。这可以用传统工具来进行(如
mpstat(1)、top(1)等)。可以通过某种模式或者某个 CPU 的高使用率情况寻找某个进程。- 如果系统时间(system time)占比高,那么可按照进程和系统调用类型来统计系统调用的频率和数量,同时检查系统调用的参数来寻找需要优化的地方(使用
perf(1)、bpftrace 单行程序,以及 BCC 工具sysstat(8))。
- 如果系统时间(system time)占比高,那么可按照进程和系统调用类型来统计系统调用的频率和数量,同时检查系统调用的参数来寻找需要优化的地方(使用
- 用性能剖析器(Profiler)来对应用程序的调用栈信息进行采样,再用 CPU 火焰图(Flame Graphs)来展示。通过分析火焰图能够捕获到很多 CPU 问题。
- 针对某个 CPU 使用率高的任务,可考虑开发一些定制工具来获取更多的上下文信息。性能剖析器通常可以展示哪些函数正在运行,但是不能展示调用参数和函数内部的信息。理解 CPU 用量时可能需要这些调用栈信息,例如:
- 内核态:如果某个文件系统针对文件进行
stat()消耗了很多 CPU 资源,那么文件名是什么?这可以用 BCC 工具statsnoop(8)来获取,也可以自行通过 BPF 工具获取。 - 用户态:如果某个应用程序忙于处理请求,那么这些请求到底是什么?如果没有针对这个程序的特定工具,可以考虑通过 USDT 或 uprobe 来开发这种工具。
- 内核态:如果某个文件系统针对文件进行
- 测量硬中断的资源消耗,但这些信息可能对基于定时器的性能剖析器不可见。可以使用 BCC 工具
hardirqs(1)解决这个问题。 - 利用程序监控计数器(PMCs,Performance Monitoring Counters)测量每时钟周期内的 CPU 指令执行量(IPC),以理解宏观层面 CPU 的阻塞情况(使用
perf(1))。还有其他的 PMC 工具可以进一步分析低缓存命中率(如 BCC 工具llcstat(8))或温控导致的阻塞等问题。
CPU 分析相关传统工具
| 工具 | 类型 | 描述 |
|---|---|---|
uptime |
内核统计 | 平均负载和系统运行时间 |
top |
内核统计 | 进程的 CPU 时间和系统层面的 CPU 模式时间 |
mpstat |
内核统计 | 显示各 CPU 的每个 CPU 模式下的时间 |
perf |
内核统计、硬件统计、事件跟踪 | 对调用栈和事件统计进行定时采样,以及对 PMCs、tracepoint、USDT 探针、kprobe 和 uprobe 进行跟踪 |
Ftrace |
内核统计、事件跟踪 | 内核函数计数统计和 kprobe、uprobe 的事件跟踪 |
CPU 分析相关 BPF 工具
| 工具 | 目标 | 描述 |
|---|---|---|
execsnoop |
调度 | 新进程的执行情况 |
exitsnoop |
调度 | 进程的寿命和退出原因 |
runqlat |
调度 | 统计 CPU 运行队列的延迟 |
runqlen |
调度 | 统计 CPU 运行队列的长度 |
runqslower |
调度 | 超过运行队列等待时长阈值的进程 |
cpudist |
调度 | 统计 on-CPU 的时间 |
cpufreq |
CPU | 通过进程采样 CPU 频率 |
profile |
CPU | 采样 CPU 调用栈 |
offcputime |
调度 | 统计 off-CPU 的调用栈和时间 |
syscount |
系统调用 | 按类型和进程统计系统调用 |
argdist |
系统调用 | 用于系统调用分析的工具 |
trace |
系统调用 | 用于系统调用分析的工具 |
funccount |
软件 | 统计函数调用 |
softirqs |
中断 | 统计软中断时间 |
hardirqs |
中断 | 统计硬中断时间 |
smpcalls |
内核 | SMP 远程 CPU 调用时间 |
llcstat |
PMCs | 按进程统计最后一级缓存(LLC)命中率 |
内存
内存分析策略
- 检查系统信息中是否有 OOM Killer 杀掉进程的信息(使用
dmesg(1))。 - 检查系统中是否配置了换页,以及使用的换页空间大小。并且检查这些换页设备是否有活跃的 I/O 操作(使用
swap(1)、iostat(1)、vmstat(1))。 - 检查系统中空闲内存的数量,以及整个系统的缓存使用情况(使用
free(1))。 - 按进程检查内存用量(使用
top(1)和ps(1))。 - 检查系统中缺页错误的发生频率,并且检查缺页错误发生时的调用栈信息,这可以解释常驻内存大小(RSS,Resident Set Size)增长的原因。
- 检查缺页错误和哪些文件有关。
- 通过跟踪
brk()和mmap()调用来从另一个角度审查内存用量。 - 使用 PMC 测量硬件缓存命空率和内存访问,以便分析导致内存 I/O 发生的函数和指令信息(使用
perf(1))。
内存分析相关传统工具
| 工具 | 类型 | 描述 |
|---|---|---|
dmesg |
内核日志 | OOM killer 事件详情 |
swapon |
内核统计 | 换页的使用情况 |
free |
内核统计 | 系统范围内内存使用情况 |
ps |
内核统计 | 进程统计信息,包括内存使用情况 |
pmap |
内核统计 | 按段(segment)查看进程的内存使用情况 |
vmstat |
内核统计 | 各种统计数据,包括内存情况 |
sar |
内核统计 | 页面错误和页面扫描速率 |
perf |
软件事件、硬件统计、硬件采样 | 内存相关 PMC 统计和事件采样 |
内存分析相关 BPF 工具
| 工具 | 目标 | 描述 |
|---|---|---|
oomkill |
OOM | 显示 OOM 事件的额外信息 |
memleak |
调度 | 统计可能的内存泄漏代码路径 |
mmapsnoop |
系统调用 | 跟踪系统范围内的 mmap(2) 调用 |
brkstack |
系统调用 | 显示带有用户调用栈的 brk() 调用 |
shmsnoop |
系统调用 | 显示共享内存调用的详细信息 |
faults |
页错误 | 按用户调用栈统计页面错误 |
ffaults |
页错误 | 按文件名统计页面错误 |
vmscan |
VM | 测量 VM 扫描程序收缩和回收时间 |
drsnoop |
VM | 跟踪直接回收事件,显示延迟 |
swapin |
VM | 按进程统计页换入信息 |
hfaults |
页错误 | 按进程统计巨页的缺页错误信息 |
文件系统
文件系统分析策略
- 先识别系统中挂载的文件系统。可使用
df(1)和mount(8)。 - 检查挂载的文件系统的容量。某些文件系统在接近 100% 使用量的时候会有性能下降的情况,这是因为它们采用的是寻找空余块的算法(例如 FFS、ZFS)。
- 在用 BPF 工具分析自己不熟悉的生产环境负载之前,可先用这些工具来分析一个已知的负载。可以找一台空闲的机器,产生一种固定的负载,再使用类似
fio(1)这样的工具来分析。 - 使用
opensnoop(8)来观察正在打开哪些文件。 - 使用
filefile(8)来检查是否存在短期文件的问题。 - 查找非常慢的文件系统操作,按进程和文件名详细观察。这可能可以帮助找到一个可以消除的负载来源,或者定量分析某个性能问题以便进行后续调优。
- 使用
ext4slower(8)、btrfsslower(8)、zfsslower(8)等,或者使用—个性能损耗可能偏高但是通用的工具,如fileslower(8)。
- 使用
- 检查文件系统的延迟分布(利用
ext4dist(8)、btrfsdist(8)、zfsdist(8)等工具)。这有可能会显示导致性能问题的延迟呈双峰分布或者离群的情况。这些问题可以继续用其他工具来进一步分析。 - 检查一段时间内页缓存的命中率(使用
cachestat(8))。检查是否其他类型的负载会改变命中率,或者是否有调优手段可以用来优化。 - 使用
vfsstat(8)来比较逻辑 I/O 和iostat(1)提供的物理 I/O 的区别。理想的情况是,逻辑 I/O 的数量应该远大于物理 I/O 的,这意味着缓存正在发挥作用。
文件系统相关传统工具
传统性能分析一般只关注磁盘的性能,所以几乎没有什么传统工具可以用来观测文件系统。下面是一些比较相关的工具。
| 工具 | 类型 | 描述 |
|---|---|---|
df |
文件系统 | 磁盘空间使用情况、磁盘挂载点 |
mount |
文件系统 | 显示和管理文件系统挂载点 |
strace |
进程 | 跟踪并记录进程的系统调用和信号 |
perf |
软件性能 | 丰富的性能分析工具,包括性能计数器、采样和跟踪功能,用于分析 CPU 和内存性能 |
fatrace |
文件系统 | 跟踪文件系统活动,包括文件的创建、删除、访问和关闭等,可用于监视文件操作事件 |
文件系统相关 BPF 工具
| 工具 | 目标 | 描述 |
|---|---|---|
opensnoop |
系统调用 | 跟踪文件的打开操作 |
statsnoop |
系统调用 | 跟踪 stat(2) 调用 |
syncsnoop |
系统调用 | 跟踪 sync(2) 和相关调用 |
mmapfiles |
系统调用 | 统计 mmap(2) 文件的数量 |
scread |
系统调用 | 统计 read(2) 文件的数量 |
fmapfault |
页缓存 | 统计文件映射的缺页错误数量 |
filelife |
VFS | 跟踪生命周期较短的文件,逐秒记录其生命周期 |
vfsstat |
VFS | 常见 VFS 操作的统计信息 |
vfscount |
VFS | 统计所有 VFS 操作的数量 |
vfssize |
VFS | VFS 读写的大小 |
fsrwstat |
VFS | 按文件系统类型的 VFS 读写 |
fileslower |
VFS | 慢速文件读写 |
filetop |
VFS | 按 IOPS 和字节数统计使用频率最高的文件 |
filetype |
VFS | 按文件类型和进程统计 VFS 读写操作 |
writesync |
VFS | 通过同步标志(sync)进行的常规文件写入 |
cachestat |
页缓存 | 页面缓存统计 |
writeback |
页缓存 | 写回事件及其延迟 |
dcstat |
Dcache | 目录缓存命中统计 |
dcsnoop |
Dcache | 跟踪目录缓存查找 |
mountsnoop |
VFS | 跟踪系统范围内的挂载和卸载操作 |
xfsslower |
XFS | 统计慢速 XFS 操作 |
xfsdist |
XFS | 常见 XFS 操作延迟直方图 |
ext4dist |
ext4 | 常见 ext4 操作延迟直方图 |
icstat |
Icache | inode 缓存命中统计 |
bufgrow |
Buffer cache | 按进程和缓存大小统计缓冲区缓存的增长 |
readahead |
VFS | 预读取的命中率和效率 |
磁盘 I/O
磁盘 I/O 分析策略
- 对应用程序性能问题来说,可以先按之前的步骤从文件系统层着手分析。
- 检查基本的磁盘性能指标:请求时长、IOPS、使用率(使用
iostat(1))。注意高使用率(仅作为参考指标)、高于常值的请求时长(延迟)和 IOPS 情况。 - 跟踪块 I/O 延迟的分布情况,检查是否有多峰分布的情况,以及延时超标的情况(使用 BCC 工具
biolatency(8))。 - 单独跟踪具体的块 I/O,找寻系统中的一些行为模式,例如是否有大量写入请求导致读队列增长等(使用 BCC 工具
biosnoop(8))。
磁盘 I/O 分析相关传统工具
| 工具 | 目标 | 描述 |
|---|---|---|
iostat |
磁盘活动 | 统计磁盘活动信息 |
perf |
块 I/O | 用于块 I/O 设备的跟踪 |
blktrace |
块设备 | 用于跟踪块设备 I/O 操作事件 |
| SCSI 日志 | SCSI 设备 | 使用系统日志查找错误超时问题 |
磁盘 I/O 分析相关 BPF 工具
| 工具 | 目标 | 描述 |
|---|---|---|
biolatency |
块 I/O | 统计块 I/O 的延迟并生成直方图 |
biosnoop |
块 I/O | 使用 PID 和延迟跟踪块 I/O |
biotop |
块 I/O | 按进程统计块 I/O(类似 top 工具) |
bitesize |
块 I/O | 按进程统计磁盘 I/O 大小的直方图 |
seeksize |
块 I/O | 统计请求的 I/O 寻址距离 |
biopattern |
块 I/O | 识别随机或顺序磁盘访问模式 |
biostacks |
块 I/O | 显示初始化调用栈的磁盘 I/O |
bioerr |
块 I/O | 跟踪磁盘错误 |
mdflush |
MD(磁盘阵列) | 跟踪 MD 刷新请求 |
iosched |
I/O 调度 | 统计 I/O 调度器的延迟 |
scsilatency |
SCSI | SCSI 命令延迟分布 |
scsiresult |
SCSI | SCSI 命令结果代码 |
nvmelatency |
NVME | 统计 NVME 驱动程序命令延迟 |
网络
网络分析策略
从对负载定性分析开始,找出低效之处(第 1、2 步),然后检查各接口的限制(第 3 步),以及不同的延迟源(第 4、5、6 步)。此后,可能可以使用实验分析法(第 7 步),但这可能会对生产负载产生影响。接下来可以使用更高级和自定义的分析工具(第 8、9 步)。
- 使用基于计数器的工具获取基本的网络统计信息:网络包速率和吞吐量。如果正在使用 TCP,那么查看 TCP 连接率和 TCP 重传率(使用
ss(8)、nstat(8)、netstat(1)和sar(1))。 - 通过跟踪新 TCP 连接的建立和时长来定性分析负载,并且寻找低效之处(使用 BCC 工具
tcplife(8))。例如读取远端资源而频繁建立的连接,可以通过本地缓存来解决。 - 检查是否到达了网卡吞吐量上限。可以使用
sar(1)或者nicstat(1)中的接口使用率指标。 - 跟踪 TCP 重传和其他的不常见 TCP 事件(使用 BCC 工具
tcpretrans(8)、tcpdrop(8),以及skb:kfree_skb跟踪点)。 - 测量主机 DNS 解析延迟。这往往是常见的性能问题(使用 BCC 工具
gethostlatency(8))。 - 从各个不同的角度测量网络延迟:连接延迟、首字节延迟、调用栈内不各层之间的延迟等。
- 注意,网络延迟测试在有不同负载的情况下可能由于网络中的缓冲区膨胀问题而有大幅变化(排队导致的延迟)。应该在有负载时和空闲时中分别测量这些延迟以进行比较。
- 使用负载生成工具来探索主机之间的网络吞吐量上限,同时检查在已知负载情况下发生的网络事件(使用
iperf(1)和netperf(1))。 - 使用高频率的 CPU 性能分析抓取内核调用栈信息,以量化 CPU 资源在网络协议和驱动程序之间的使用情况。
- 使用 tracepoint 和 kprobe 来探索网络协议栈的内部情况。
在监测内核网络事件时需要注意:
- 网络事件可能不在应用程序上下文中触发。收到数据包时,可能是其他线程正在 CPU 上执行,而且这时可能有 TCP 连接建立和状态的改变。如果在这些事件发生时检查在 CPU 上执行的 PID 和进程名,并不能获取到对应的应用程序信息。这时需要选择那些在应用程序上下文中触发的事件,或者使用某个标识符(例如使用
sock结构体)来缓存应用程序上下文信息,后续再读取。 - 系统中可能存在快路径和慢路径之分。如果一段程序只跟踪其中一个路径,看起来也能够正常工作。所以这个时候就需要使用一些已知的负载来确保包数量和字节数量与预期相符。
- TCP 中有满套接字(full sockets)和不满套接字(non-full sockets)之分:不满套接字指的是三次握手没有完成之前的套接字,或者是处于
TIME_WAIT状态的套接字。在不满套接字中,socket 结构体的有些字段可能处于无效状态。
网络分析相关传统工具
| 工具 | 类型 | 描述 |
|---|---|---|
ss |
内核层面统计 | 套接字统计 |
ip |
内核层面统计 | IP 统计 |
nstat |
内核层面统计 | 网络栈统计 |
netstat |
内核层面统计 | 综合工具,用于统计网络协议栈的信息和状态 |
sar |
内核层面统计 | 综合工具,用于统计网络和其他信息 |
nicstat |
内核层面统计 | 网卡信息统计 |
ethtool |
驱动层面统计 | 网卡驱动统计 |
tcpdump |
抓包 | 捕获数据包以供分析 |
iperf |
微基准测试 | 网络分析 |
netperf |
微基准测试 | 网络分析 |
ping |
ICMP | 网络可达性分析 |
traceroute |
路由发现 | 路由分析 |
/proc 文件系统 |
内核层面统计 | 统计多种网络信息 |
网络分析相关 BPF 工具
| 工具 | 目标 | 描述 |
|---|---|---|
sockstat |
套接字 | 高层级的套接字统计 |
sofamily |
套接字 | 按进程统计新套接字的地址族 |
soprotocol |
套接字 | 按进程统计新套接字的传输协议 |
soconnect |
套接字 | 跟踪套接字 IP 协议连接过程的详细信息 |
soaccept |
套接字 | 跟踪套接字 IP 协议接受过程的详细信息 |
socketio |
套接字 | 统计套接字细节与 I/O |
socksize |
套接字 | 按进程统计套接字 I/O 大小的直方图 |
sormem |
套接字 | 统计套接字接收缓冲区使用情况和溢出 |
soconnlat |
套接字 | 统计 IP 套接字连接延迟,并附带调用栈 |
so1stbyte |
套接字 | 统计 IP 套接字首字节延迟 |
tcpconnect |
TCP | 跟踪 TCP 主动连接(connect()) |
tcpaccept |
TCP | 跟踪 TCP 被动连接(accept()) |
tcplife |
TCP | 跟踪 TCP 会话生命周期,包括连接详细信息 |
tcptop |
TCP | 按主机地址显示 TCP 发送/接收吞吐量 |
tcpretrans |
TCP | 跟踪 TCP 重传,包括地址和 TCP 状态 |
tcpsynbl |
TCP | 统计 TCP SYN 队列直方图 |
tcpwin |
TCP | 跟踪 TCP 发送拥塞窗口参数 |
tcpnagle |
TCP | 跟踪 TCP Nagle 使用和传输延迟 |
udpconnect |
UDP | 跟踪本地主机的新 UDP 连接 |
gethostlatency |
DNS | 通过库调用跟踪 DNS 查找延迟 |
ipecn |
IP | 跟踪入站(inbound)显式拥塞通知 |
superping |
ICMP | 从网络协议栈中测量 ICMP 回显时间 |
qdisc-fq (...) |
qdisc | 统计 FQ qdisc 队列延迟 |
netsize |
网络 | 统计网络设备 I/O 大小 |
nettxlat |
网络 | 统计网络设备传输延迟 |
skbdrop |
skbs | 跟踪 sk_buff 丢弃,包括内核调用栈 |
skblife |
skbs | 跟踪 sk_buff 的生命周期,包括调用栈内延迟 |
ieee80211scan |
WiFi | 跟踪 IEEE 802.11 WiFi 扫描 |
安全
这里所说的安全指的是安全分析、安全监控和策略执行。目前也有一些 BPF 工具可用于这个目的。
| 工具 | 目标 | 描述 |
|---|---|---|
execsnoop |
系统调用 | 列出新进程的执行情况 |
elfsnoop |
内核 | 显示 ELF 文件加载情况 |
modsnoop |
内核 | 显示内核模块加载情况 |
bashreadline |
bash | 列出输入的 bash shell 命令 |
shellsnoop |
shells | 镜像 shell 的输出 |
ttysnoop |
TTY | 镜像 tty 的输出 |
opensnoop |
系统调用 | 列出打开的文件 |
eperm |
系统调用 | 统计失败的 EPERM 和 EACCES 系统调用 |
tcpconnect |
TCP | 跟踪外发 TCP 连接(主动) |
tcpaccept |
TCP | 跟踪入站 TCP 连接(被动) |
tcpreset |
TCP | 显示 TCP 发送重置,监测端口扫描 |
capable |
安全 | 跟踪内核安全权限检查 |
setuids |
系统调用 | 跟踪 setuid 系统调用(特权升级) |
编程语言
对编程语言级别的监测一般可以在编写应用程序代码时确定,在运行时收集数据。但是这种方式灵活性差,不能在程序运行时修改监测逻辑,但好处是监测过程由业务逻辑和开发者意愿决定,因此这部分不在本文的范围内。
一共有三种不同原理的编程语言:
- 编译型语言(如 C、C++、Golang、Rust、Pascal、Fortran 和 COBOL 等):代码会被编译为机器码,并且保存在二进制可执行文件中。
- 即时编译型语言(如 Java、JavaScript、Julia、.Net 和 Smalltalk 等):代码编译为字节码,在运行时阶段再编译为机器码。
- 解释型语言(如 Bash 脚本、Perl、Python 和 Ruby 等):不会将程序函数编译为机器码,而是使用自身内置的子函数进行语法分析和执行。
编程语言分析策略
- 确定语言是如何执行的。应用是被编译为二进制文件、还是在运行时即时编译、还是解释执行,或者以一种混合的方式执行。
- 浏览本章提供的工具和单行程序,理解对于每种语言类型可以做的事情。
- 在互联网上搜索是否存在已知的工具,并查找如何使用 BPF 对语言进行分析。
- 检查该语言是否有 USDT 探针(在 CPU 的章节中提到过),确定它们是否在发行的二进制版本中被启用(或者重新编译以启用它们)。USDT 是稳定的插桩位置。
- 写一个样例程序来进行插桩。调用一个有确定名字和确定延迟(例如使用
sleep生成延迟)的函数,这样就可以通过检查这些工具是否能够识别这些已知的量,来检查它们是否能正常工作。 - 对于用户态的软件,可以使用 uprobe 来对语言的执行过程进行监控。对于内核态软件则使用 kprobe。
编程语言分析相关 BPF 工具
对于 C 语言(编译型语言):
| 工具 | 目标 | 描述 |
|---|---|---|
funccount |
函数级别 | 统计函数调用 |
stackcount |
调用栈级别 | 统计本机事件的调用栈 |
trace |
函数级别 | 打印函数调用和返回值,及详细信息 |
argdist |
函数级别 | 统计函数参数或返回值 |
bpftrace |
所有 | 在任何调用栈插桩自定义的监测函数 |
监控 C++ 的方式和监控 C 几乎一样,但需要考虑一些不同点:
- 符号改变,比如
ClassLoader::initialize()会编译为ZN11ClassLoader10initializeEv。 - 为了支持对象和
self对象,某些函数参数可能不会遵守处理器 ABI。
对于 Java 语言(即时编译型语言):
| 工具 | 目标 | 描述 |
|---|---|---|
jnistacks |
libjvm | 通过监测对象调用栈(object stack)显示 JNI 调用者 |
profile |
CPU | 基于时间的调用栈监测,包括 Java 方法函数 |
offcputime |
调度 | 统计 off-CPU 时间及其调用栈信息,包括 Java 方法函数 |
stackcount |
事件 | 显示给定事件的调用栈 |
javastat |
USDT | 高级语言操作统计 |
javathreads |
USDT | 跟踪线程启动和停止事件 |
javacalls |
USDT | 统计 Java 方法调用 |
javaflow |
USDT | 显示 Java 方法代码流程 |
javagc |
USDT | 跟踪 Java 垃圾回收 |
javaobjnew |
USDT | 统计 Java 新对象分配 |
对于 Bash 脚本(解释型语言):
| 工具 | 目标 | 描述 |
|---|---|---|
bashfunc |
bash | 监控 bash 函数调用 |
bashfunclat |
bash | 监控 bash 函数调用的耗时 |
另外,对于 Go 语言,由于它也是编译型语言,所以监控方式也和 C 语言类似,但是在函数调用规范、协程和动态的栈管理方面有一些重要的区别。但可以通过其他方式在对 Go 程序进行调试和跟踪,包括 gdb 的 Go 运行时支持、Go 运行时跟踪器,以及使用 gctrace 和 schedtrace 并启用 GODEBUG。此外,也可以监控函数执行测试、函数入口参数函数返回值等。目前,也有面向 Go 语言的 USDT 探针工具 Salp。
应用
应用分析策略
- 确定应用程序的工作单元;确定改进性能意味着什么,是更高的吞吐量、更低的延迟,或者更低的资源使用率
- 确定应用组件的相关信息。例如,使用的程序库、使用的缓存等。同时查找应用程序 API 文档,以及描述应用程序请求处理过程的信息(比如线程池模型、事件处理器模型或其他模型)。
- 确定是否有影响性能的后台计划任务(比如每 30 秒运行一次的磁盘写入事件)。
- 检查 USDT 探针是否支持该应用程序和它所使用的编程语言。
- 执行 on-CPU 分析来理解 CPU 消耗情况,并确定导致低效的位置(使用 BCC 工具
profile(8))。 - 执行 off-CPU 分析来理解为什么应用程序阻塞。关注应用程序处理请求时的阻塞时间,并定位可以优化的领域(使用 BCC 工具
offcputime(8)、wakeuptime(8)、offwaketime(8))。 - 分析系统调用,理解一个应用程序的资源使用情况(使用 BCC 工具
syscount(8))。 - 使用 uprobe 探索应用程序的内部运行机制。比如 on-CPU 和 off-CPU 调用栈分析可以定位到很多方法,这些方法可以作为跟踪的起点。
- 对分布式计算来说,要考虑对服务器端和客户端同时进行跟踪。比如在跟踪 MySQL 请求时,需要同时追踪客户端和服务器端。
应用分析相关 BPF 工具
| 工具 | 目标 | 描述 |
|---|---|---|
execsnoop |
调度 | 列出新进程的执行情况 |
threadsnoop |
pthread | 列出新线程的创建情况 |
profile |
CPUs | on-CPU 的调用栈采样 |
threaded |
CPUs | on-CPU 的线程采样 |
offcputime |
调度 | 统计 off-CPU 时间及其调用栈 |
offcpuhist |
调度 | 统计 off-CPU 时间的调用栈和时间直方图 |
syscount |
系统调用 | 按类型统计系统调用 |
ioprofile |
I/O | 统计 I/O 上的调用栈 |
mysqld_qslower |
MySQL 服务器 | 显示慢于某个阈值的 MySQL 查询 |
mysqld_clat |
MySQL 服务器 | 统计 MySQL 命令延迟的直方图 |
signals |
信号 | 按目标进程统计发送的信号 |
killsnoop |
系统调用 | 显示 kill(2) 系统调用发送者的详细信息 |
pmlock |
锁 | 统计 pthread 互斥锁的锁定时间和用户函数调用栈 |
pmheld |
锁 | 统计 pthread 互斥锁的持有时间和用户函数调用栈 |
naptime |
系统调用 | 显示自愿休眠调用 |
deadlock |
锁 | 寻找潜在的死锁 |
内核
内核分析策略
- 创建可以触发相关事件的工作负载,知道确定的触发次数。
- 检查现有对该事件插桩的跟踪点或者工具。
- 如果该事件会被频繁调用,占用较多的 CPU 资源(>5%),那么 CPU 剖析可以快速查看涉及的内核函数。如果不是频繁调用的事件,长时间的剖析可以捕捉足够多的样本(使用
perf(1)或者 BCCprofile(8),配合 CPU 火焰图使用)。CPU 剖析还会展示自旋锁的使用,以及乐观自旋期间的互斥锁。 - 另一个探寻相关内核函数的方法是,对可能会匹配事件的函数进行计数。例如正在分析 ext4 文件系统的事件,可以尝试统计所有匹配
ext4_*的函数(使用 BCC 工具funccount(8))。 - 对来自内核函数的调用栈计数,以了解代码路径(使用 BCC 工具
stackcount(8))。如果进行了 CPU 剖析,那么这些代码路径应该与之相符。 - 通过子事件跟踪函数调用流(使用 perf-tools 中基于 Ftrace 的
funcgraph(8))。 - 检查函数参数(使用 BCC 工具
trace(8)和argdist(8),或者bpftrace)。 - 测量函数延迟(使用 BCC 工具
funclatency(8)或者bpftrace)。 - 编写一个自定义工具对事件插桩,并打印或总结它们。
内核分析相关传统工具
| 工具 | 类型 | 描述 |
|---|---|---|
Ftrace |
性能跟踪 | Linux 内置跟踪器 |
perf sched |
性能跟踪 | Linux 官方性能分析器:调度器分析子命令 |
slabtop |
内核统计 | 内核 slab 缓存使用情况 |
内核分析相关 BPF 工具
| 工具 | 目标 | 描述 |
|---|---|---|
loads |
CPU | 显示平均负载 |
offcputime |
调度 | 统计 off-CPU 调用栈和时间 |
wakeuptime |
调度 | 统计唤醒者的调用栈和阻塞时间 |
offwaketime |
调度 | 统计唤醒者的 off-CPU 调用栈 |
mlock |
互斥锁 | 统计互斥锁锁定时间及其内核调用栈 |
mheld |
互斥锁 | 统计互斥锁持有时间及其内核调用栈 |
kmem |
内存 | 统计内核内存分配 |
kpages |
内存页 | 统计内核页面分配 |
memleak |
内存 | 统计可能的内存泄漏代码路径 |
slabratetop |
Slab | 按缓存统计内核 slab 分配速率 |
numamove |
NUMA | 显示 NUMA 页面迁移统计 |
workq |
工作队列 | 统计工作队列函数执行时间 |
容器
这里谈到的容器指的是通过 Linux 命名空间进行隔离、通过 cgroups 进行资源控制的虚拟化技术。在这个场景下,所有容器共享宿主机内核、共享宿主机的资源。此外也有硬件级别的虚拟化容器,可以为每个容器虚拟出一个内核,例如 Kata Containers、Firecracker。
容器分析策略
- 检查系统是否存在硬件资源瓶颈以及前文介绍过的 CPU、内存等问题。尤其要为正在运行的应用程序创建 CPU 火焰图。
- 检查是否遇到了 cgroups 软限制。
- 浏览和运行上文列举过的全部 BPF 工具。
容器分析相关传统工具
从宿主机上分析:
| 工具 | 类型 | 描述 |
|---|---|---|
systemd-cgtop |
内核统计 | 用于 cgroups 的 top 工具 |
kubectl top |
内核统计 | 用于 Kubernetes 资源的 top 工具 |
docker stats 或 crictl stats |
内核统计 | 容器的资源使用情况 |
/sys/fs/cgroups 文件系统 |
内核统计 | 原始 cgroups 统计数据 |
perf |
性能分析和统计 | 支持 cgroups 过滤器的多功能跟踪工具 |
从容器内分析:
| 工具 | 描述 |
|---|---|
top |
注意:进程列表是容器内的进程信息,而上方的资源摘要是主机的对应资源状态 |
ps |
显示容器进程 |
uptime |
显示主机统计信息,包括主机负载平均值 |
mpstat |
显示主机 CPU 和主机 CPU 使用情况 |
vmstat |
显示主机 CPU、内存和其他统计信息 |
iostat |
显示主机磁盘信息 |
free |
显示主机内存信息 |
容器分析相关 BPF 工具
| 工具 | 目标 | 描述 |
|---|---|---|
runqlat |
调度 | 按 PID 命名空间统计 CPU 运行队列延迟 |
pidnss |
调度 | 统计 PID 命名空间切换(面向共享 CPU 的容器) |
blkthrot |
块 I/O | 统计被 blk cgroup 限制的块 I/O |
overlayfs |
Overlay 文件系统 | 显示 Overlay 文件系统的读写延迟 |
虚拟机
虚拟机分析策略
对于访客系统(guest):
- 插桩监测超级调用以检查是否有过多操作。
- 检查 CPU 被盗用的时长。
- 使用前文涉及的工具进行资源分析。需要注意的是,这些是虚拟资源,它们的性能可能会受到虚拟机管理器或硬件的资源限制,并且也可能受其他访客系统资源竞争的影响。
对于宿主机系统(host):
- 插桩监测虚拟机的退出行为(VM-EXIT)以检查是否有过多操作。
- 如果使用了 I/O 代理(QEMU),插桩该代理的工作负载和延迟。
- 使用前文介绍的工具进行资源分析。
虚拟机分析相关传统工具
对于 KVM,perf(1) 有一个子命令可以查看事件分析报告:perf kvm stat live。
虚拟机分析相关 BPF 工具
如果访客系统使用半虚拟化,并使用超级调用,它们就可以使用现存的工具插桩:funccount(8)、trace(8)、argdist(8) 和 stackcount(8)。
| 工具 | 目标 | 描述 |
|---|---|---|
xenhyper |
访客系统 | 计算并显示 Xen 访客系统中的超级调用次数 |
cpustolen |
访客系统 | 统计被窃取的 CPU 时间的分布 |
kvmexits |
宿主机 | 统计访客系统不同原因的退出时间分布 |
技巧与建议
事件频率
下面是系统中的一些常见操作及其典型的触发频率。表项『缩放的频率』是将系统事件频率类比成个人日常生活中接受邮件的频率,用来直观感受事件发生的频繁程度。
| 事件 | 典型频率 | 缩放的频率 | 估计的跟踪开销 |
|---|---|---|---|
| 线程休眠 | 每秒 1 次 | 每年一次 | 忽略不计 |
| 进程执行 | 每秒 10 次 | 每月一次 | 忽略不计 |
| 文件打开 | 每秒 10–50 次 | 每周一次 | 忽略不计 |
| 以 100 Hz 进行采样 | 每秒 100 次 | 每周两次 | 忽略不计 |
| 新建 TCP 连接 | 每秒 10–500 次 | 每天一次 | 忽略不计 |
| 磁盘 I/O | 每秒 10–1000 次 | 每天三次 | 忽略不计 |
| VFS 调用 | 每秒 1000–10,000 次 | 每小时一次 | 可测量 |
| 系统调用 | 每秒 1000–50,000 次 | 每十分钟一次 | 重要 |
| 网络数据包 | 每秒 1000–100,000 次 | 每五分钟一次 | 重要 |
| 内存分配 | 每秒 10,000–1,000,000 次 | 每三十秒一次 | 昂贵 |
| 锁定事件 | 每秒 50,000–5,000,000 次 | 每五秒一次 | 昂贵 |
| 函数调用 | 每秒 100,000,000 次 | 每秒三次 | 极高 |
| CPU 指令 | 每秒 1,000,000,000+ 次 | 每秒三十次 | 极高(仅存在于仿真场景中) |
| CPU 周期 | 每秒 3,000,000,000+ 次 | 每秒九十次 | 极高(仅存在于仿真场景中) |
BPF 操作成本
通过 BPF 插桩也会不可避免地给系统带来额外的资源消耗,并且不同的 BPF 操作所带来的性能损耗也各不相同。下面是通过 dd(1) 工具,在引入不同的插桩任务时,执行一百万次读操作的耗时,用来测试不同的 BPF 操作的时间成本。
| bpftrace | 测试目的 | 运行时间(秒) | 每事件成本(ns) |
|---|---|---|---|
| 无 | 对照 | 5.97243 | - |
k:vfs_read { 1 } |
Kprobe | 6.75364 | 76 |
kr:vfs_read { 1 } |
Kretprobe | 8.13894 | 212 |
t:syscalls:sys_enter_read { 1 } |
Tracepoint | 6.95894 | 96 |
t:syscalls:sys_exit_read { 1 } |
Tracepoint | 6.9244 | 93 |
u:libc:__read { 1 } |
Uprobe | 19.1466 | 1287 |
ur:libc:__read { 1 } |
Uretprobe | 25.7436 | 1931 |
k:vfs_read /arg2 > 0/ { 1 } |
过滤 | 7.24849 | 124 |
k:vfs_read { @ = count() } |
Map | 7.91737 | 190 |
k:vfs_read { @[pid] = count() } |
单个 key | 8.09561 | 207 |
k:vfs_read { @[comm] = count() } |
以字符串为 key | 8.27808 | 225 |
k:vfs_read { @[pid, comm] = count() } |
以两个值作为 key | 8.3167 | 229 |
k:vfs_read { @[kstack] = count() } |
以内核态调用栈为 key | 9.41422 | 336 |
k:vfs_read { @[ustack] = count() } |
以用户态调用栈为 key | 12.648 | 652 |
k:vfs_read { @ = hist(arg2) } |
直方图 | 8.35566 | 233 |
k:vfs_read { @s[tid] = nsecs } kr:vfs_read /@s[tid]/ { @ = hist(nsecs - @s[tid]); delete(@s[tid]); } |
计时 | 12.4816 | 636 / 2 |
k:vfs_read { @[kstack, ustack] = hist(arg2) } |
多个操作 | 14.5306 | 836 |
k:vfs_read { printf("%d bytes\n", arg2) } > out.txt |
输出每个事件 | 14.6719 | 850 |
注:测试环境是启用即时编译 BPF 的 Linux 4.15、Intel(R) Core(TM) i7-8650U CPU @ 1.90GHz CPUs。为了一致性使用 taskset(1) 绑定到一个 CPU 上进行测试,并取最快的 10 次运行(最小扰动原理),同时检查标准偏差的一致性。
实操建议
- 采用非常规的频率进行采样(如 99Hz),避免采样频率和某些固有频率共振,影响测量准确性。
- 采用一个不常见且区分度较大的数字(如 17、23)来模拟工作负载,用来在监测事件频率时确定对应负载会触发哪些事件。
- 系统调用常常可以用来进行跟踪。系统调用有丰富的手册文档,甚至包括传入参数和返回值。
- kprobe 和 uprobe 的签名不稳定,会存在维护风险。因此尽可能保持程序简单,便于维护。
- 需要注意插桩的事件是不是真正触发的事件。例如如果应用程序是静态编译的,那么对应的共享库中的函数将并不会被触发。
- 监测时的调用栈缺失可能是因为编译器进行了性能优化,没有欲流寄存器 RBP 给栈指针,导致解析失败。解决办法就是通过编译参数或 Java 启动参数修复帧指针寄存器。
- 符号缺失的问题一方面可能由于调用栈损坏,第二个原因是短时进程(符号查询未完毕就退出了),第三个原因是没有可用的符号表(对于二进制文件,一方面可以调整构建过程避免去除符号;另一方面可以从其他来源获取符号信息,比如 BTF 或 debuginfo)。
- 找不到插桩的函数。可能是由于符号缺失,也有可能是因为编译器性能优化或其他原因:函数内联、尾调用优化、静态和动态链接等。
- 注意不要产生事件回路:
bpftrace -e 'k:ext4_file_write_iter{ printf(...) }' > /ext4fs/out.file。 - 事件频率过高时,可能会导致 perf 缓冲区溢出,丢失事件。
声明
本文首发于:tech.wuzy.cn,欢迎在评论区讨论交流。
本文主要参考、引用、修改自 Brendan Gregg 的《BPF Performance Tools》。
性能分析方法论及策略——传统方法与 BPF 方法